Introducción
 Con la finalidad de diseñar una red de voz, en esta cuarta unidad de los Aspectos Clave de la Conectividad de Redes (ACCR), vamos a integrar y aplicar todo lo aprendido hasta aquí, considerando todos los factores que pueden afectar la calidad de las conversaciones. El objetivo (pulse sobre la figura para agrandarla) es que usted sepa cómo se dimensiona una red de VoIP, calculando tanto el ancho de banda de una llamada, como el número de troncales requeridas por el tráfico telefónico.
Con la finalidad de diseñar una red de voz, en esta cuarta unidad de los Aspectos Clave de la Conectividad de Redes (ACCR), vamos a integrar y aplicar todo lo aprendido hasta aquí, considerando todos los factores que pueden afectar la calidad de las conversaciones. El objetivo (pulse sobre la figura para agrandarla) es que usted sepa cómo se dimensiona una red de VoIP, calculando tanto el ancho de banda de una llamada, como el número de troncales requeridas por el tráfico telefónico.
Dinámica del Curso
A lo largo de la exposición y en la sección de comentarios, estaré proponiendo ejercicios y un taller para que al término de la entrada/curso, usted pueda responder a mis preguntas o me haga saber el resultado de mis encomiendas, a través de sus comentarios. En algunos casos, usted investigará por su cuenta algunos temas para reafirmar y ampliar sus conocimientos. A fin de complementar su capacitación, encontrará un vínculo para descargar contenido multimedia (animaciones y audio) sin ningún costo. Para que no se pierda de los detalles de cada apartado, le recomiendo que conforme vaya avanzando en su lectura, haga clic sobre cada figura para agrandarla.
Conocimientos previos
Para comprender mejor todo lo que hemos de estudiar en esta unidad, es importante tener bien claros los conocimientos de las unidades anteriores. Si usted ya conoce los conceptos básicos de la tecnología de VoIP, entonces creo que no tendrá ningún problema para asimilar el material que vamos a analizar aquí; pero si ya no se acuerda bien de dichos fundamentos o siente que todavía no los domina, entonces es muy probable que quiera descargar el Repaso de las Unidades II y III de ACCR, que si bien no sustituye en modo alguno la totalidad de los contenidos de los ACCR anteriores, sí le ayudará a entender mejor los temas que siguen.

Factores a considerar en el diseño.
Es imposible obviar la importancia que van a tener el tipo de codec, el tamaño de la muestra, la tecnología de capa 2 (encabezados) sobre la que se encapsularán los paquetes de voz , la compresión de esos encabezados vía el protocolo CRTP, así como la detección inteligente de la actividad de voz (VAD, por sus siglas en inglés). Véase la figura 2, haciendo clic sobre la misma para agrandarla.
El codec lo selecciona usted en cada uno los gateways de su red. A este respecto, conviene aclarar que este curso no es sobre telefonía IP, a la que podríamos concebir como un abanico de funciones de valor agregado que un IP PBX ofrece a sus usuarios, y que funciona gracias a la tecnología de Voz sobre IP (véase el repaso). Pero en una red de VoIP los protagonistas no son los IP PBXs, sino los gateways y los puntos terminales como los softphones y los teléfonos IP. Con esto en mente, un gateway de gama alta o de calidad similar, le permitirá  configurar el tipo de codec, en función de las características que he relacionado en la figura 3 (derecha). No hay que perder de vista que para que una llamada pueda establecerse en una red VoIP, es indispensable que los codecs en ambos extremos manejen exactamente el mismo estándard; así por ejemplo, usted no podrá llamar desde un teléfono analógico conectado a una intefaz FXS de un gateway que tenga configurado un codec G.711, a otro usuario que esté conectado a un puerto con el estándard G.729. Ahora bien, en cursos anteriores vimos que un codec podría comprimir la carga útil a diferentes velocidades (tasas de compresión), y que cada uno de ellos tenía un MOS (Mean Opinion Score) diferente, que era un indicador de la calidad de voz percibida, en toda la extensión de la palabra, porque el MOS es una forma muy subjetiva de medir la calidad. Vimos también que si bien era importante reducir el consumo de ancho de banda (porque redundaba en un ahorro en las igualas mensuales de los enlaces), al mismo tiempo existía un compromiso entre la calidad del codec y el ancho de banda propio de la compresión. Lo que quiero decir es que mientras más se comprima la carga útil (las muestras de voz, no los encabezados), la calidad del codec tiende a ser más pobre. Lo que se necesita entonces es un codec que comprima a una tasa de compresión razonable, y que al mismo tiempo sea de buena calidad. Asi mismo, tasas de compresión muy altas, exigen una gran capacidad de procesamiento, lo cual va a impactar a su vez en los retardos que se darán por esa razón en los gateways. Y esto también deberá usted tenerlo muy presente cuando tenga que decidir qué codec usar, pues si va a comprimir a una gran velocidad, tendrá que disponer de gateways con procesadores suficientemente rápidos
configurar el tipo de codec, en función de las características que he relacionado en la figura 3 (derecha). No hay que perder de vista que para que una llamada pueda establecerse en una red VoIP, es indispensable que los codecs en ambos extremos manejen exactamente el mismo estándard; así por ejemplo, usted no podrá llamar desde un teléfono analógico conectado a una intefaz FXS de un gateway que tenga configurado un codec G.711, a otro usuario que esté conectado a un puerto con el estándard G.729. Ahora bien, en cursos anteriores vimos que un codec podría comprimir la carga útil a diferentes velocidades (tasas de compresión), y que cada uno de ellos tenía un MOS (Mean Opinion Score) diferente, que era un indicador de la calidad de voz percibida, en toda la extensión de la palabra, porque el MOS es una forma muy subjetiva de medir la calidad. Vimos también que si bien era importante reducir el consumo de ancho de banda (porque redundaba en un ahorro en las igualas mensuales de los enlaces), al mismo tiempo existía un compromiso entre la calidad del codec y el ancho de banda propio de la compresión. Lo que quiero decir es que mientras más se comprima la carga útil (las muestras de voz, no los encabezados), la calidad del codec tiende a ser más pobre. Lo que se necesita entonces es un codec que comprima a una tasa de compresión razonable, y que al mismo tiempo sea de buena calidad. Asi mismo, tasas de compresión muy altas, exigen una gran capacidad de procesamiento, lo cual va a impactar a su vez en los retardos que se darán por esa razón en los gateways. Y esto también deberá usted tenerlo muy presente cuando tenga que decidir qué codec usar, pues si va a comprimir a una gran velocidad, tendrá que disponer de gateways con procesadores suficientemente rápidos 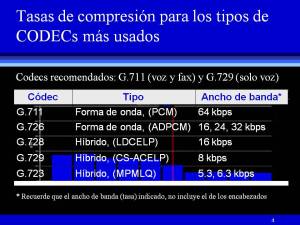 (muchas veces costosos) para cumplir con sus requerimientos de ancho de banda. La pregunta que surge entonces es: ¿cuáles serían los codecs que deberíamos usar en una aplicación de VoIP, para que todo vaya bien?. Por favor haga clic en la figura 4 (izquierda) para ver mi sugerencia. Advierta que si únicamente va a estar estableciendo y manteniendo sesiones de voz (conversaciones), lo más aconsejable es utilizar el codec G.729, pues éste cumple con los requerimientos anteriormente mencionados (un ancho de banda relativamente reducido con un MOS prácticamente igual al del codec G.711, que es el de mayor calidad). No obstante, e independientemente de que existan codecs especiales para faxes (de la serie T de la UIT), usted tendrá que configurar en sus equipos el estándard G.711 de la UIT, si quiere que sus gateways soporten tanto transmisiones de voz como de fax.
(muchas veces costosos) para cumplir con sus requerimientos de ancho de banda. La pregunta que surge entonces es: ¿cuáles serían los codecs que deberíamos usar en una aplicación de VoIP, para que todo vaya bien?. Por favor haga clic en la figura 4 (izquierda) para ver mi sugerencia. Advierta que si únicamente va a estar estableciendo y manteniendo sesiones de voz (conversaciones), lo más aconsejable es utilizar el codec G.729, pues éste cumple con los requerimientos anteriormente mencionados (un ancho de banda relativamente reducido con un MOS prácticamente igual al del codec G.711, que es el de mayor calidad). No obstante, e independientemente de que existan codecs especiales para faxes (de la serie T de la UIT), usted tendrá que configurar en sus equipos el estándard G.711 de la UIT, si quiere que sus gateways soporten tanto transmisiones de voz como de fax.
 El tamaño de la muestra también es configurable, y se define como el número de bytes que alcanza a capturar el codec en un intervalo de tiempo que está entre los 10 y los 30 milisegundos (al menos esos son los tamaños que Cisco maneja en sus gateways, aunque no dudo que existan fabricantes de equipos que soporten valores ligeramente diferentes).
El tamaño de la muestra también es configurable, y se define como el número de bytes que alcanza a capturar el codec en un intervalo de tiempo que está entre los 10 y los 30 milisegundos (al menos esos son los tamaños que Cisco maneja en sus gateways, aunque no dudo que existan fabricantes de equipos que soporten valores ligeramente diferentes).
Si no queremos que nuestros paquetes se retrasen demasiado, o que resulte difícil el recuperarlos, deberíamos escoger tamaños de muestra pequeños. Pero el elegir muestras pequeñas, implica inundar los canales de comunicación (enlaces) con un mayor número de encabezados, lo cual va en detrimento del desempeño (throughput) de la red. Lo contrario aplica para las muestras de voz muy grandes (ver figura 5). En esta misma figura he apuntado que con muestras grandes, el jitter aumenta, lo cual no es del todo aconsejable. El jitter se puede definir como la variabilidad de los retardos y afecta sensiblemente la calidad de las conversaciones. Se percibe como una interrupción momentánea de una palabra o frase y si llega a ser excesivo, la conversación se vuelve ininteligible. No debe confundirse con la pérdida de paquetes, cuyo rango de aceptación o tolerancia se recomienda se mantenga igual o menor al 1% entre paquetes contiguos y del orden del 3% entre paquetes no muy próximos.
Con el tamaño de la muestra también existe un compromiso entre los factores mencionados, de manera que también es bueno conocer el criterio a seguir para seleccionar correctamente este parámetro. Salvo muy contadas excepciones, conviene apegarse a lo que dice el refrán «ni tanto que queme al santo, ni tanto que no lo alumbre», lo que traducido a la jerga técnica viene a ser un tamaño de muestra de 20 msegs. De hecho, es el valor de fábrica (default) que maneja Cisco en sus gateways (pasarelas).
 Los encabezados repercuten significativamente en el ancho de banda, ya que no es lo mismo encapsularlos sobre ethernet, que sobre PPP, MPLS, o junto con alguna otra tecnología que contribuya con el aumento de lo que también se conoce como overhead, como pueden ser los túneles con IPSec o L2TP. A esos encabezados hay desde luego que agregar los de los protocolos de red (IP) y de transporte (UDP y RTP), que invariablemente estarán presentes en todas las aplicaciones no solo de voz, sino de aquellas en las que se deba transportar datos de tiempo real y multimedia (video y audio). Como sabemos de la Unidad I, a este proceso necesario de agregado de encabezados (overhead) a la carga útil, se le conoce como encapsulamiento, y el total de bytes que necesita cada paquete para ser enviado y procesado convenientemente a través de la red, repercute en el rendimiento (throughput) de la misma. Cuando la relación (carga útil)/encabezados aumenta, el rendimiento de la red es mayor que cuando ese mismo cociente disminuye. Si concebimos a los encabezados como la información que necesitamos para tramitar el envío de cada paquete, parece claro que entre más carga útil logremos enviar con menor número de trámites, estaremos aprovechando mejor el ancho de banda disponible. Por el contrario, si enviamos muy pocos datos realmente útiles (carga útil o payload) con demasiados trámites (overhead), estaremos desaprovechando nuestro ancho de banda y por lo tanto, tendremos un bajo rendimiento. Dice el refrán popular: «mucho ruido y pocas nueces».
Los encabezados repercuten significativamente en el ancho de banda, ya que no es lo mismo encapsularlos sobre ethernet, que sobre PPP, MPLS, o junto con alguna otra tecnología que contribuya con el aumento de lo que también se conoce como overhead, como pueden ser los túneles con IPSec o L2TP. A esos encabezados hay desde luego que agregar los de los protocolos de red (IP) y de transporte (UDP y RTP), que invariablemente estarán presentes en todas las aplicaciones no solo de voz, sino de aquellas en las que se deba transportar datos de tiempo real y multimedia (video y audio). Como sabemos de la Unidad I, a este proceso necesario de agregado de encabezados (overhead) a la carga útil, se le conoce como encapsulamiento, y el total de bytes que necesita cada paquete para ser enviado y procesado convenientemente a través de la red, repercute en el rendimiento (throughput) de la misma. Cuando la relación (carga útil)/encabezados aumenta, el rendimiento de la red es mayor que cuando ese mismo cociente disminuye. Si concebimos a los encabezados como la información que necesitamos para tramitar el envío de cada paquete, parece claro que entre más carga útil logremos enviar con menor número de trámites, estaremos aprovechando mejor el ancho de banda disponible. Por el contrario, si enviamos muy pocos datos realmente útiles (carga útil o payload) con demasiados trámites (overhead), estaremos desaprovechando nuestro ancho de banda y por lo tanto, tendremos un bajo rendimiento. Dice el refrán popular: «mucho ruido y pocas nueces».
 Como los encabezados son indispensables para realizar todos esos trámites, habrá situaciones en la que resulte difícil obtener un buen rendimiento, por lo que habrá que recurrir a otras instancias, como por ejemplo, reducir encabezados. Los encabezados de la triada inseparable RTP/UDP/IP (léase RTP sobre UDP sobre IP), es posible reducirlos de 40 bytes, como mostraba la figura 6, a solo 2 bytes, como se ha ilustrado en la figura de la derecha (hacer clic para agrandarla). ¿Y cómo es eso posible?. Si usted ya conoce la respuesta, lo invito a que la remita a la sección de comentarios. Si no la conoce, por favor investigue en la red y envíela al final de esta entrada(curso) a modo de comentario, como parte de la dinámica que le ayudará a reafirmar y ampliar sus conocimientos.
Como los encabezados son indispensables para realizar todos esos trámites, habrá situaciones en la que resulte difícil obtener un buen rendimiento, por lo que habrá que recurrir a otras instancias, como por ejemplo, reducir encabezados. Los encabezados de la triada inseparable RTP/UDP/IP (léase RTP sobre UDP sobre IP), es posible reducirlos de 40 bytes, como mostraba la figura 6, a solo 2 bytes, como se ha ilustrado en la figura de la derecha (hacer clic para agrandarla). ¿Y cómo es eso posible?. Si usted ya conoce la respuesta, lo invito a que la remita a la sección de comentarios. Si no la conoce, por favor investigue en la red y envíela al final de esta entrada(curso) a modo de comentario, como parte de la dinámica que le ayudará a reafirmar y ampliar sus conocimientos.
A partir de esta misma figura y a modo de comentario, proporcione la memoria de cálculo para determinar cuántos Bytes captura un codec G.711 en 10 msegs (tamaño de la muestra). Compruebe su resultado comparándolo con el dato que aparece en la columna Bytes/muestra.
 Hay una función que los gateways soportan y que ayuda a optimizar el flujo de paquetes de voz, suprimiendo los silencios. ¿Para qué enviar paquetes de silencio hasta el otro extremos de la red, si éstos no aportan mensajes útiles al receptor?. A la capacidad que tiene un gateway para ahorrar aproximadamante un 35% de ancho de banda, por medio de la supresión de silencios, se le llama Detección de Actividad de Voz (VAD, por sus siglas en ingés); pero como bien se advierte en la figura 8 (izquierda), no debe ser usada como criterio para dimensionar el ancho de banda de los enlaces de la red, debido a que ese ahorro solo aplica cuando se trata de tráficos muy densos (por arriba de las mil llamadas). La razón principal es que, en el curso de una conversación, los silencios son completamente impredecibles.
Hay una función que los gateways soportan y que ayuda a optimizar el flujo de paquetes de voz, suprimiendo los silencios. ¿Para qué enviar paquetes de silencio hasta el otro extremos de la red, si éstos no aportan mensajes útiles al receptor?. A la capacidad que tiene un gateway para ahorrar aproximadamante un 35% de ancho de banda, por medio de la supresión de silencios, se le llama Detección de Actividad de Voz (VAD, por sus siglas en ingés); pero como bien se advierte en la figura 8 (izquierda), no debe ser usada como criterio para dimensionar el ancho de banda de los enlaces de la red, debido a que ese ahorro solo aplica cuando se trata de tráficos muy densos (por arriba de las mil llamadas). La razón principal es que, en el curso de una conversación, los silencios son completamente impredecibles.
Para calcular el ancho de banda requerido en una red de VoIP, debemos calcular primero el que va a consumir una  sola llamada, y luego multiplicar ese valor, por el número de llamadas simultáneas que podrán ser transmitidas por la red. Esas llamadas que pueden establecerse y mantenerse en una red de VoIP de manera simultánea, equivale al concepto de troncales en la telefonía tradicional, y ese concepto es el que usaremos para determinar el ancho de banda total, como sigue:
sola llamada, y luego multiplicar ese valor, por el número de llamadas simultáneas que podrán ser transmitidas por la red. Esas llamadas que pueden establecerse y mantenerse en una red de VoIP de manera simultánea, equivale al concepto de troncales en la telefonía tradicional, y ese concepto es el que usaremos para determinar el ancho de banda total, como sigue:
Ancho de banda Total = Ancho de banda de una llamada x número de troncales ……………….(1)
Cálculo del ancho de banda de una llamada
En la telefonía tradicional, las troncales son los canales que conectan dos centrales cualesquiera, ya sean éstas públicas (Central Offices, o COs) o privadas (PBX o conmutadores). A las troncales que conectan dos centrales privadas o PBX se les denomina Tie Lines, o troncales privadas; a las que interconectan dos COs, se les llama troncales públicas; y las que conectan un PBX con una CO, se conocen simplemente como troncales.
 Para comprender mejor el procedimiento de cálculo del ancho de banda de una llamada, hagamos un ejercicio con valores reales. En la figura de la derecha, hemos ejemplificado el procedimiento suponiendo que vamos a trabajar en una red ethernet, con un codec G.711 y muestras de 30 msegs.
Para comprender mejor el procedimiento de cálculo del ancho de banda de una llamada, hagamos un ejercicio con valores reales. En la figura de la derecha, hemos ejemplificado el procedimiento suponiendo que vamos a trabajar en una red ethernet, con un codec G.711 y muestras de 30 msegs.
Aconsejo razonar de la siguiente manera para no tratar de memorizar ningún dato y comprender mejor la relación entre el tipo de codec y el tamaño de la muestra (30 msegs en este ejemplo).
Lo primero que hay que hacer es preguntarse, ¿Cuales son las unidades en las que está dado el ancho de banda?. Puesto que el resultado debe estar dado en bits por segundo (Kbps, Mbps, Gbps, etc.), y sabiendo que el codec está «viendo pasar» 64,000 bits en un segundo (G.711), entonces cabría preguntarse cuántos bits alcanzaría a ver el codec en tan solo 30 msegs, que es la ventana de tiempo que se le está dando para capturar cada muestra. El problema de reduce a una simple regla de tres, tal y como he ilustrado en la figura 10. Dicho en otras palabras, si 64,000 bits pasan en un segundo, ¿cuántos bits pasarán en 0.030 segundos? El resultado es 240 bytes. Las figuras 5, 7 y 8 así lo corroboran.
 Pero recuerde que esos 240 bytes corresponden solo a la carga útil, pues es la cantidad de bytes que ha digitalizado el codec vía el proceso PCM, según se vio en las Unidades II y III de la serie ACCR. Así que ya tenemos la parte de la voz. Ahora falta incluir la información que ya dijimos nos sirve para tramitar el envío de los paquetes, es decir, los encabezados. Volviendo de nuevo a la figura 6, advertimos que la triada RTP/UDP/IP aporta 40 bytes a los encabezados, mientras que ethernet agrega otros 18, de manera que sumados con la carga útil y dividiendo todos esos 298 bytes entre el tamaño de la muestra en segundos, arroja un total de 79.5 Kbps.
Pero recuerde que esos 240 bytes corresponden solo a la carga útil, pues es la cantidad de bytes que ha digitalizado el codec vía el proceso PCM, según se vio en las Unidades II y III de la serie ACCR. Así que ya tenemos la parte de la voz. Ahora falta incluir la información que ya dijimos nos sirve para tramitar el envío de los paquetes, es decir, los encabezados. Volviendo de nuevo a la figura 6, advertimos que la triada RTP/UDP/IP aporta 40 bytes a los encabezados, mientras que ethernet agrega otros 18, de manera que sumados con la carga útil y dividiendo todos esos 298 bytes entre el tamaño de la muestra en segundos, arroja un total de 79.5 Kbps.
Si comprimiéramos esos encabezados, reemplazaríamos en la misma ecuación, los 40 bytes de la triada RTP/UDP/IP por tan solo 2 bytes producto de la compresión, que en este caso se 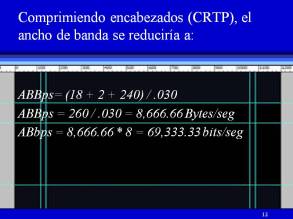 implementa en las interfaces seriales de los gateways, mediante el protocolo CRTP (Compressed RTP), que a su vez es activado mediante un comando que usted como administrador deberá teclear desde su consola de configuración, de manera similar a como lo hizo en los laboratorios virtuales de las tres unidades anteriores. ¿Cual es ese comando? Por favor conteste a esta pregunta con un comentario al final de esta entrada, haciendo el ejercicio de investigación que corresponda.
implementa en las interfaces seriales de los gateways, mediante el protocolo CRTP (Compressed RTP), que a su vez es activado mediante un comando que usted como administrador deberá teclear desde su consola de configuración, de manera similar a como lo hizo en los laboratorios virtuales de las tres unidades anteriores. ¿Cual es ese comando? Por favor conteste a esta pregunta con un comentario al final de esta entrada, haciendo el ejercicio de investigación que corresponda.
Tráfico telefónico
Se conoce como tráfico al número promedio de ocupaciones simultáneas durante un periodo de tiempo T, que generalmente corresponde a los 60 minutos de la llamada hora pico.
A la unidad de tráfico se le dio el nombre de erlang, en honor al matemático, estadístico e ingeniero Danés, Agner Krarup Erlang, y está representada por la fracción o porcentaje de la hora pico, durante la cual una o más líneas  se mantuvieron ocupadas. En la figura 13 se dan algunos ejemplos que nos ayudan a entender mejor cómo se mide el tráfico telefónico. Por lo geeral, el número de erlangs de tráfico en un sistema de VoIP, depende de la naturaleza de la organización o empresa en donde la red se encuentra instalada. Cuando se desea conocer el tráfico de un sistema que apenas se va a instalar, se pueden realizar estimaciones del número de erlangs, en base a estadísticas de otros negocios o instituciones similares. Típicamente, en un ambiente de oficinas gubernamentales, comercios, bancos, etc., se puede asumir que, en promedio, los abonados realizan cinco llamadas de tres minutos cada una, durante la hora pico, por lo que el tráfico por extensión resulta ser de 0.25 Erlangs. En otros entornos, como el doméstico por ejemplo, los valores estarán en el rango de los 0.07 a los 0.1 erlangs. En los de mayor alto tráfico, como es el caso de la bolsa de valores y los centros de llamadas (ver modelo C de Erlang en el Anexo II), estos números alcanzarán hasta los 0.5 erlangs. ¿Y cómo deberíamos interpretar un valor de 0.5 Erlangs por extensión?. Significa que durante la hora pico, esa linea se ocupó por 30 minutos (no necesariamente en una sola ocasión, sino probablemente distribuidos en varias llamadas a lo largo de ese tiempo). ¿Y cómo saber cuál es la hora pico?. Son los 60 minutos que corresponden al mes de más alto tráfico, y dentro de ese mes, la semana, el día y la hora cuyo tráfico resultó ser el mayor de todos.
se mantuvieron ocupadas. En la figura 13 se dan algunos ejemplos que nos ayudan a entender mejor cómo se mide el tráfico telefónico. Por lo geeral, el número de erlangs de tráfico en un sistema de VoIP, depende de la naturaleza de la organización o empresa en donde la red se encuentra instalada. Cuando se desea conocer el tráfico de un sistema que apenas se va a instalar, se pueden realizar estimaciones del número de erlangs, en base a estadísticas de otros negocios o instituciones similares. Típicamente, en un ambiente de oficinas gubernamentales, comercios, bancos, etc., se puede asumir que, en promedio, los abonados realizan cinco llamadas de tres minutos cada una, durante la hora pico, por lo que el tráfico por extensión resulta ser de 0.25 Erlangs. En otros entornos, como el doméstico por ejemplo, los valores estarán en el rango de los 0.07 a los 0.1 erlangs. En los de mayor alto tráfico, como es el caso de la bolsa de valores y los centros de llamadas (ver modelo C de Erlang en el Anexo II), estos números alcanzarán hasta los 0.5 erlangs. ¿Y cómo deberíamos interpretar un valor de 0.5 Erlangs por extensión?. Significa que durante la hora pico, esa linea se ocupó por 30 minutos (no necesariamente en una sola ocasión, sino probablemente distribuidos en varias llamadas a lo largo de ese tiempo). ¿Y cómo saber cuál es la hora pico?. Son los 60 minutos que corresponden al mes de más alto tráfico, y dentro de ese mes, la semana, el día y la hora cuyo tráfico resultó ser el mayor de todos.
Clases de tráfico
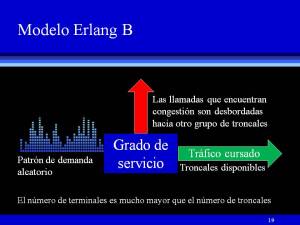
 Dependiendo de cual sea el resultado que un abonado obtenga cuando intenta realizar una llamada, el tráfico que manejará el sistema puede ser de dos clases: el tráfico cursado y el tráfico ofrecido. El tráfico cursado es el que se asocia al conjunto de llamadas que salen del sistema o que efectivamente pasó por el mismo. En conformidad con esta definición, decimos que todas las llamadas que tuvieron éxito durante el proceso de conexión con el destino, son parte del tráfico cursado (ver más adelante figuras 19 y 20). El tráfico ofrecido (figura 14) es aquél que se asocia a las llamadas que demandan los usuarios y que encuentran algún problema al intentar la conexión con el destino, como por ejemplo,
Dependiendo de cual sea el resultado que un abonado obtenga cuando intenta realizar una llamada, el tráfico que manejará el sistema puede ser de dos clases: el tráfico cursado y el tráfico ofrecido. El tráfico cursado es el que se asocia al conjunto de llamadas que salen del sistema o que efectivamente pasó por el mismo. En conformidad con esta definición, decimos que todas las llamadas que tuvieron éxito durante el proceso de conexión con el destino, son parte del tráfico cursado (ver más adelante figuras 19 y 20). El tráfico ofrecido (figura 14) es aquél que se asocia a las llamadas que demandan los usuarios y que encuentran algún problema al intentar la conexión con el destino, como por ejemplo,  errores de marcación, congestión (ver figura 15) o cualesquier otro desperfecto del sistema que ocasione un fracaso durante la comunicación entre ambas partes. La congestión o bloqueo de líneas se presenta cuando una llamada no puede establecerse porque todos los dispositivos de conexión están ocupados. Las llamadas que se ofrecen al sistema y que encuentran congestión en el mismo se denominan llamadas perdidas (figura 16). La probabilidad de que una llamada se pierda va a depender del grado de servicio que el administrador desee para su sistema. El establecer una probabilidad de pérdida de llamadas con el propósito de diseñar nuestra red de VoIP, trae consigo un compromiso entre el costo y
errores de marcación, congestión (ver figura 15) o cualesquier otro desperfecto del sistema que ocasione un fracaso durante la comunicación entre ambas partes. La congestión o bloqueo de líneas se presenta cuando una llamada no puede establecerse porque todos los dispositivos de conexión están ocupados. Las llamadas que se ofrecen al sistema y que encuentran congestión en el mismo se denominan llamadas perdidas (figura 16). La probabilidad de que una llamada se pierda va a depender del grado de servicio que el administrador desee para su sistema. El establecer una probabilidad de pérdida de llamadas con el propósito de diseñar nuestra red de VoIP, trae consigo un compromiso entre el costo y  la eficiencia del mismo. Para ejemplificar lo anterior, supóngase que un administrador ha decidido que de cada 100 llamadas que un abonado intente realizar, existe la posibilidad de que sólo una de ellas se pierda. La probabilidad de pérdida en este caso es del 1% y lo que se tiene aquí es un sistema en extremo eficiente; sólo que a un precio excesivamente alto. La mayoría de los administradores de sistemas experimentan gran contrariedad cuando se enteran del número de troncales que se necesitan para alcanzar ese grado de servicio. Por ello, la probabilidad de pérdida o congestión la fijan de acuerdo a los recursos de que disponen, y de qué tan bien quieren que se comporte el sistema al poner a prueba la disponibilidad de sus troncales (figura 15). Así, el administrador deberá establecer el criterio de diseño que más se ajuste a sus recursos, exigencias y necesidades.
la eficiencia del mismo. Para ejemplificar lo anterior, supóngase que un administrador ha decidido que de cada 100 llamadas que un abonado intente realizar, existe la posibilidad de que sólo una de ellas se pierda. La probabilidad de pérdida en este caso es del 1% y lo que se tiene aquí es un sistema en extremo eficiente; sólo que a un precio excesivamente alto. La mayoría de los administradores de sistemas experimentan gran contrariedad cuando se enteran del número de troncales que se necesitan para alcanzar ese grado de servicio. Por ello, la probabilidad de pérdida o congestión la fijan de acuerdo a los recursos de que disponen, y de qué tan bien quieren que se comporte el sistema al poner a prueba la disponibilidad de sus troncales (figura 15). Así, el administrador deberá establecer el criterio de diseño que más se ajuste a sus recursos, exigencias y necesidades.
Determinación del número de troncales (tablas y modelos de Erlang)
Al igual que en otras áreas de la ingeniería, existen en la literatura datos tabulados que ahorran un gran número de cálculos y que se emplean precisamente en el diseño de este tipo de sistemas. Tal es el caso de las tablas de Erlang. Como se advierte en la figura adjunta, n es el número de troncales que nos está haciendo falta en la ecuación (1) para calcular el ancho de banda total de nuestros enlaces de voz, pues hasta ahora, apenas hemos aprendido a obtener el ancho de banda que ocuparía una sola llamada.
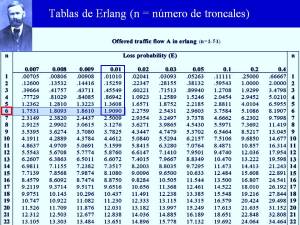 Hay dos formatos para las tablas de Erlang. El que se ha mostrado en la figura 17, se usa para determinar el número de troncales (n), una vez que se ha establecido el grado de servicio y se ha calculado el tráfico ofrecido. Para entender cómo se usa este formato, supongamos que el número de llamadas durante la hora pico hubiese sido de 60, con un promedio de duración de 2 minutos. De acuerdo con la ecuación dada en la figura 14, el tráfico ofrecido sería de:
Hay dos formatos para las tablas de Erlang. El que se ha mostrado en la figura 17, se usa para determinar el número de troncales (n), una vez que se ha establecido el grado de servicio y se ha calculado el tráfico ofrecido. Para entender cómo se usa este formato, supongamos que el número de llamadas durante la hora pico hubiese sido de 60, con un promedio de duración de 2 minutos. De acuerdo con la ecuación dada en la figura 14, el tráfico ofrecido sería de:
A = C * T = 60 x 2 = 120 llamadas-minuto
Recordando también de esa misma figura que el tráfico en erlangs se obtiene simplemente dividiendo A entre los 60 minutos que tiene la hora pico, tenemos:
erlangs = 120/60 = 2 erlangs.
Si asumimos un grado de servicio de 1%, al entrar a las Tablas de Erlangs de la figura 17, notamos que si recorremos hacia abajo, la columna correspondiente a una probabilidad de pérdida de 0.01, hasta encontrar el valor que más se aproxima a 2 erlangs (en este caso es 1.9090), el valor n que se encuentra enmarcado en rojo a la izquierda de ese renglón, es 6. Ese es el número de troncales correspondiente a esos erlangs de tráfico, para el grado de servicio seleccionado en este ejemplo (1%).
Existe otro formato que se usa para evaluar el rendimiento de un sistema ya instalado (red, mas terminales, más gateways, más PBX o IPPBX, etc.). En un taller que más adelante pondré a su amable consideración en la sección de comentarios, le voy a pedir que investigue cómo se usa esa presentación para determinar el grado de servicio de una red, conociendo el número de troncales y habiendo calculado previamente el tráfico ofrecido. La evaluación del rendimiento se realiza con la finalidad de conocer qué tan bien está operando la red, con el número de troncales que se tienen en ese momento.
Taller No. 1: Un caso práctico
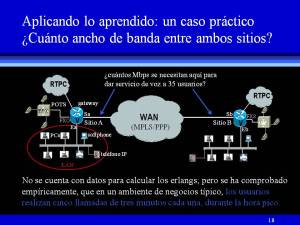 No hay mejor manera de aprender que con casos reales. A continuación voy a explicar cómo se diseña la Red Voip mostrada en la figura 18 (derecha), para que entre ambos sitios se puedan establecer y mantener conversaciones con una excelente calidad de servicio (QoS), a través de una WAN de tecnología MPLS/PPP. Concretamente, se trata de especificar el ancho de banda entre los sitios A y B, para que 35 usuarios puedan llamar de un extremo a otro sin hacer uso de la red telefónica pública conmutada (RTPC).
No hay mejor manera de aprender que con casos reales. A continuación voy a explicar cómo se diseña la Red Voip mostrada en la figura 18 (derecha), para que entre ambos sitios se puedan establecer y mantener conversaciones con una excelente calidad de servicio (QoS), a través de una WAN de tecnología MPLS/PPP. Concretamente, se trata de especificar el ancho de banda entre los sitios A y B, para que 35 usuarios puedan llamar de un extremo a otro sin hacer uso de la red telefónica pública conmutada (RTPC).
Aplicando lo que ya hemos visto en apartados anteriores, procedamos a calcular el ancho de banda de una llamada, considerando un codec G.729 y un tamaño de muestra de 20 msegs, que como ya habíamos acordado, son las mejores opciones, ya que no necesitaremos transmitir faxes.
El tamaño de la muestra en bytes la obtenemos a partir de la regla de tres simple:
8,000 bits/1 seg = Xbits/0.020 segs
Xbits = (8,000 x 0.020) = 160 bits
Xbytes = 160/8 = 20 bytes.
Utilizando ese valor para la carga útil, calculemos el ancho de banda por llamada, incluyendo los encabezados de PPP y de la triada de transporte y red, que esta vez comprimiremos (ver figuras 6 y 7):
ABBps = (6+2+20) bytes/0.020 seg
ABBps = 28/0.020 = 1,400 bytes/seg
ABbps = 1,400 x 8 = 11,200 bits/seg = 11.2 Kbps
Note que no hemos incluido los encabezados del protocolo MPLS, ya que estamos haciendo el cálculo de los enlaces entre los sitios del cliente y la WAN, no en la nube del proveedor. Las etiquetas inherentes a MPLS no son agregadas por el router del cliente, sino en el router de frontera (E-LSR) de la WAN, por lo que no existen encabezados de esta tecnología en los enlaces A y B.
 Necesitamos conocer ahora el número de troncales para calcular el ancho de banda total. Puesto que no disponemos del número de llamadas durante la hora pico (C) ni de la duración promedio de una llamada en minutos (T), no podemos obtener el tráfico ofrecido con la fórmula A = C * T. Pero como hemos visto, en un ambiente de negocios típico, propio de un modelo erlang B/B extendido, para el que el número de extensiones es mucho mayor que el de troncales, los usuarios hacen cinco llamadas de tres minutos cada una en la hora pico, lo que significa que su extensión la ocupan 15 minutos durante dicho intervalo de observación, que divididos entre 60 minutos, da un tráfico de 0.25 erlangs por usuario. Si multiplicamos ese valor por el total de usuarios, el tráfico ofrecido es A = 0.25 erlangs x 35 = 8.75 erlangs. En el estudio de tráfico del Anexo I fundamento aún más el porqué es muy válido, confiable y recomendable, el asignar este valor empírico al número de erlangs por extensión, cuando no se cuenta con ningún dato y el modelo de
Necesitamos conocer ahora el número de troncales para calcular el ancho de banda total. Puesto que no disponemos del número de llamadas durante la hora pico (C) ni de la duración promedio de una llamada en minutos (T), no podemos obtener el tráfico ofrecido con la fórmula A = C * T. Pero como hemos visto, en un ambiente de negocios típico, propio de un modelo erlang B/B extendido, para el que el número de extensiones es mucho mayor que el de troncales, los usuarios hacen cinco llamadas de tres minutos cada una en la hora pico, lo que significa que su extensión la ocupan 15 minutos durante dicho intervalo de observación, que divididos entre 60 minutos, da un tráfico de 0.25 erlangs por usuario. Si multiplicamos ese valor por el total de usuarios, el tráfico ofrecido es A = 0.25 erlangs x 35 = 8.75 erlangs. En el estudio de tráfico del Anexo I fundamento aún más el porqué es muy válido, confiable y recomendable, el asignar este valor empírico al número de erlangs por extensión, cuando no se cuenta con ningún dato y el modelo de 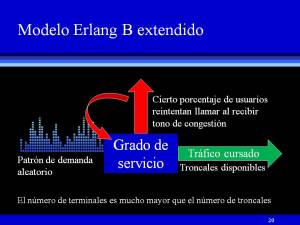 Erlang que aplica para el caso en cuestión es el B, o el B extendido (hacer clic en figuras 19 y 20).
Erlang que aplica para el caso en cuestión es el B, o el B extendido (hacer clic en figuras 19 y 20).
Considerando un grado de servicio del 1%, que es lo que generalmente se recomienda cuando se tienen los recursos y se precisa optimizar la calidad de servicio telefónico, podemos entrar a las tablas de Erlang con ese valor (0.01) y el tráfico estimado de 8.75 erlangs, para determinar el número de troncales que necesitamos. Si consultamos la tabla de la figura 17, vemos que con 16 troncales podemos garantizar ese grado de servicio.
Multiplicando el número de troncales por el ancho de banda de cada llamada, tenemos:
ABtotal = 16 x 11.2 Kbps = 179.2 Kbps.
Los buenos administradores de redes suelen agregar un 10% extra de ancho de banda y no precisamente por «si las moscas», sino porque se hace necesario dar cabida también a ese flujo de paquetes que inyecta el protocolo de control de tiempo real (RTCP, por sus siglas en ingés) para manejar el control de las llamadas. Incluyendo este ancho de banda tenemos:
ABtotal (c/cntrl) = 179.2 x 1.1 = 197.12 Kbps
Puesto que no debemos olvidarnos de los datos, es indispensable sumar el ancho de banda que debimos haber estimado previamente para nuestras aplicaciones (web, transferencia de archivos, correo electrónico, etc). Tan solo para ilustrar cuál sería el procedimiento que seguiríamos para escoger un enlace de valor comercial, que sería lo que tendríamos que hacer en un caso real, supongamos que hemos estimado unos 500 Kbps para el ancho de banda de nuestras aplicaciones de datos. Ahora nuestro ancho de banda total sería de:
ABtotal (c/ctrl + datos) = 197.12 + 500 = 697.12 Kbps.
Por último, podríamos considerar otro ancho de banda extra para dar cabida a otros recursos de la red, en conformidad con una de las muchas buenas prácticas que Cisco recomienda seguir. Lo que hemos calculado hasta aquí, corresponde al 75% de la capacidad que debería tener nuestro enlace, sin incluir el ancho de banda asociado al soporte de los picos de tráfico, y al de la administración y control de la red en general. Atendiendo a esta recomendación, usted tendría que reservar ese 25% restante, para dar un gran total de ancho de banda de:
AB_TOTAL = 697.12 Kbps/0.75 = 929.5 Kbps
El valor comercial más cercano a nuestras necesidades sería entonces de 1 Mbps.
Anexo I: Estudio de Tráfico
Un caso real que ratifica lo adecuado que resulta el considerar el valor empírico de 0.25 erlangs por extensión, en un ambiente de negocios típico (modelo Erlang B extendido).
 A continuación le proporciono la memoria de cálculo del estudio de tráfico que elaboré a principios del año 2001 para Pond’s, una prestigiada firma de la industria de productos para el cuidado y la estética de la piel, con domicilio conocido en la Ciudad Industrial del Valle de Cuernavaca (CIVAC).
A continuación le proporciono la memoria de cálculo del estudio de tráfico que elaboré a principios del año 2001 para Pond’s, una prestigiada firma de la industria de productos para el cuidado y la estética de la piel, con domicilio conocido en la Ciudad Industrial del Valle de Cuernavaca (CIVAC).
Por aquel entonces, (supongo que hoy en día ya tendrán un sistema mucho más moderno), Pond’s brindaba servicio a sus empleados con un PBX de la marca Alcatel-Indetel, modelo 5200-BCS, al que se encontraban conectadas un total de 131 extensiones.
Mediante una consulta a la base de datos del PBX en cuestión, me fue posible obtener los erlangs por extensión, de acuerdo con las ecuaciones proporcionadas por el fabricante (Alcatel), esto es:
En un tiempo de observación de 2 minutos:
Erlangs = reg 44 / (120 x número de extensiones)
En un tiempo de observación de una hora :
Erlangs = (reg 47 x 32767 + reg 48 + reg 45 x 32767 + reg 46) / (3600 x no. de extensiones)
en donde reg 44, reg 45, reg 46, reg 47 y reg 48 son los contenidos de los registros 44, 45, 46, 47 y 48 de la tabla de contabilización de tráfico total (externo e interno) ofrecido al 5200 BCS por sus extensiones.
Sustituyendo los valores consultados hallamos que :
Para 2 minutos :
Erlangs = 3890 / (120×131) = 0.2474
Para una hora de observación :
Erlangs = (2x 32,767 + 11,455 + 1 x 32,767 + 1) / (3,600 x 131) = 0.2327
Tomando este último valor de 0.2327 y denotando a A como el tráfico total ofrecido al sistema., tenemos :
A = 0.2327 x número de extensiones = 0.2327 x 131 = 30.48 Erlangs
Criterio de diseño no.1 : Congestión/Grado de Servicio = 1 %
Con los valores 30.48 (tráfico) y 0.01 (congestión o probabilidad de pérdida), entramos a la tablas de Erlang y observamos que la intersección de esos dos valores se cumple para un número de circuitos n = 42 troncales.
Criterio de diseño no. 2 : Congestión = 10 %
Procedemos de manera análoga pero ahora buscando un valor de n para el cual, A=30.48 y E=0.1. Ahora el número de troncales necesarias es de 32.
 Pond’s en realidad contaba por aquel entonces con 18 troncales. Para evaluar el sistema en esas condiciones, bastó con consultar las tablas de Erlang en su presentación de evaluación, a partir de las cuales se obtuvo una congestión del 44.6%. Como se ha visto, esto significaba que «de cada 100 llamadas que intentaba realizar un empleado de la compañía, era probable que 45 de ellas se perdieran durante la hora pico. Cuando le comuniqué al administrador los resultados de mi estudio, me dijo que si les decía a los directivos que necesitaba comprar más del doble de troncales para mejorar la calidad del servicio telefónico en Pond’s, seguramente lo despedirían. Le tuve que decir que los números no mentían, y que yo tampoco. No podía hacerles creer que con unas pocas líneas más, las cosas iban a cambiar significativamente.
Pond’s en realidad contaba por aquel entonces con 18 troncales. Para evaluar el sistema en esas condiciones, bastó con consultar las tablas de Erlang en su presentación de evaluación, a partir de las cuales se obtuvo una congestión del 44.6%. Como se ha visto, esto significaba que «de cada 100 llamadas que intentaba realizar un empleado de la compañía, era probable que 45 de ellas se perdieran durante la hora pico. Cuando le comuniqué al administrador los resultados de mi estudio, me dijo que si les decía a los directivos que necesitaba comprar más del doble de troncales para mejorar la calidad del servicio telefónico en Pond’s, seguramente lo despedirían. Le tuve que decir que los números no mentían, y que yo tampoco. No podía hacerles creer que con unas pocas líneas más, las cosas iban a cambiar significativamente.
Anexo II: Modelo de Erlang C
Los centros de llamadas que emplean funciones como la distribución automática de llamadas (ACD) y el Interactive Voice Responde (IVR), no son sistemas telefónicos en donde tenga cabida el modelo B o B extendido de Erlang. Para ser objetivos, los call centers no están pensados para ofrecer un mejor servicio a sus clientes, sino más bien se diseñaron para que los centros de atención (CACs) pierdan menos clientes de los que podrían perder si el servicio se implementara de acuerdo con el modelo B. Es más probable que usted permanezca en la línea y no cuelgue, cuando llama a una compañía en donde la llamada es contestada por una operadora automática, que si usted llama y recibe tono de congestión («ocupado»). En este segundo caso, la reacción automática de cualquier persona es colgar. Cada vez que esto sucede, la compañía pierde un cliente potencial.
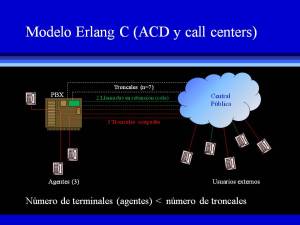 Para retener a sus clientes potenciales, los call centers necesitan forzosamente de más líneas troncales que agentes, tal y como se ha mostrado en la figura adjunta, a fin de que puedan poner en retención aquellas llamadas que han superado el número de conversaciones simultáneas que los agentes pueden manejar. En el ejemplo mostrado (haga clic en la figura para agrandarla), cada uno de los tres agentes está atendiendo a un cliente cuando un sexto prospecto llama. Como ya no hay más agentes que puedan atender a este otro cliente potencial, esta llamada es retenida en una cola de espera. Al colgar alguno de los agentes, la llamada que en ese momento esté encabezando la cola se ofrecerá a ese agente para que la conteste. A este esquema de funcionamiento se le conoce como modelo de Erlang C.
Para retener a sus clientes potenciales, los call centers necesitan forzosamente de más líneas troncales que agentes, tal y como se ha mostrado en la figura adjunta, a fin de que puedan poner en retención aquellas llamadas que han superado el número de conversaciones simultáneas que los agentes pueden manejar. En el ejemplo mostrado (haga clic en la figura para agrandarla), cada uno de los tres agentes está atendiendo a un cliente cuando un sexto prospecto llama. Como ya no hay más agentes que puedan atender a este otro cliente potencial, esta llamada es retenida en una cola de espera. Al colgar alguno de los agentes, la llamada que en ese momento esté encabezando la cola se ofrecerá a ese agente para que la conteste. A este esquema de funcionamiento se le conoce como modelo de Erlang C.
 Los multímetros, los cautines, los osciloscopios, los desarmadores y demás herramientas que un técnico en electrónica o un ingeniero precisan en su lugar de trabajo, siguen siendo medios necesarios para la consecución de los fines para los que fueron concebidos; pero como yo lo veo, esas herramientas convencionales distan mucho de ser suficientes. Solo asómese a YouTube y vea lo que un profesional en esta esfera de actividad es capaz de hacer, y comprenderá mejor lo que quiero decir: la competencia es feroz.
Los multímetros, los cautines, los osciloscopios, los desarmadores y demás herramientas que un técnico en electrónica o un ingeniero precisan en su lugar de trabajo, siguen siendo medios necesarios para la consecución de los fines para los que fueron concebidos; pero como yo lo veo, esas herramientas convencionales distan mucho de ser suficientes. Solo asómese a YouTube y vea lo que un profesional en esta esfera de actividad es capaz de hacer, y comprenderá mejor lo que quiero decir: la competencia es feroz. Ya en ensayos anteriores expliqué cómo es que una máquina aprende a reparar equipos electrónicos y cómo puede usted aprovechar esa inteligencia artificial para montar un taller que lo distinga de toda esa miríada de competidores que mencioné con anterioridad. Porque si usted hace un excelente trabajo en menos tiempo y a un menor costo, tenga la seguridad de que ello redundará en un mayor número de recomendaciones de boca en boca.
Ya en ensayos anteriores expliqué cómo es que una máquina aprende a reparar equipos electrónicos y cómo puede usted aprovechar esa inteligencia artificial para montar un taller que lo distinga de toda esa miríada de competidores que mencioné con anterioridad. Porque si usted hace un excelente trabajo en menos tiempo y a un menor costo, tenga la seguridad de que ello redundará en un mayor número de recomendaciones de boca en boca. Pronto comenzaremos a ver máquinas inteligentes que reparan otras, y quizás en un futuro cercano, máquinas que se reparan así mismas. Y no estoy hablando de ciencia ficción. Si hoy en día su servidor ya pudo implementar una herramienta para reparar hornos de microondas con WEKA, no veo por qué no, los electrodomésticos de la próxima generación ya vengan equipados con mecanismos tolerantes a fallas, que les permitan recuperarse después de una descompostura, sin la intervención de un técnico calificado. Independientemente del costo que implique su fabricación y lo factible que pueda llegar a ser su demanda, los aparatos de la próxima generación van a contribuir de manera significativa a
Pronto comenzaremos a ver máquinas inteligentes que reparan otras, y quizás en un futuro cercano, máquinas que se reparan así mismas. Y no estoy hablando de ciencia ficción. Si hoy en día su servidor ya pudo implementar una herramienta para reparar hornos de microondas con WEKA, no veo por qué no, los electrodomésticos de la próxima generación ya vengan equipados con mecanismos tolerantes a fallas, que les permitan recuperarse después de una descompostura, sin la intervención de un técnico calificado. Independientemente del costo que implique su fabricación y lo factible que pueda llegar a ser su demanda, los aparatos de la próxima generación van a contribuir de manera significativa a  mejorar nuestro medio ambiente (el consumidor promedio ha sido aleccionado para usar y desechar todo lo que compra). Pero bueno, haciendo a un lado las ventajas ecológicas y todos los demás beneficios y polémicas que pudiera suscitar el empleo de semejantes piezas de ingeniería, hoy por hoy ya podemos echar mano de programas de computadora para transformar una PC o una laptop, en una herramienta inteligente que ayuda a reparar equipos electrónicos de todo tipo.
mejorar nuestro medio ambiente (el consumidor promedio ha sido aleccionado para usar y desechar todo lo que compra). Pero bueno, haciendo a un lado las ventajas ecológicas y todos los demás beneficios y polémicas que pudiera suscitar el empleo de semejantes piezas de ingeniería, hoy por hoy ya podemos echar mano de programas de computadora para transformar una PC o una laptop, en una herramienta inteligente que ayuda a reparar equipos electrónicos de todo tipo. WEKA es un programa de cómputo (software) que la Universidad de Waikato desarrolló para que personas como usted y como yo pudiéramos analizar e interpretar datos, sin conocer a fondo los algoritmos matemáticos que emplea la minería de datos. WEKA es el acrónimo de Waikato Environment for Knowledge Analysis, que significa “Entorno de la Universidad de Waikato para el Análisis del Conocimiento”, y es un software libre distribuido bajo la licencia GNU-GPL.
WEKA es un programa de cómputo (software) que la Universidad de Waikato desarrolló para que personas como usted y como yo pudiéramos analizar e interpretar datos, sin conocer a fondo los algoritmos matemáticos que emplea la minería de datos. WEKA es el acrónimo de Waikato Environment for Knowledge Analysis, que significa “Entorno de la Universidad de Waikato para el Análisis del Conocimiento”, y es un software libre distribuido bajo la licencia GNU-GPL. En la imagen adjunta presento la pantalla que WEKA desplegó inmediatamente después de haberle pedido que abriera el historial de reparaciones cuyo formato especifiqué en mi ensayo anterior. El diagrama de barras que aparece en esta misma captura de pantalla proporciona un informe del número de casos que en cada reparación, correspondió a una marca de horno de microondas en particular (pulse sobre la imagen para agrandarla). Así por ejemplo, vemos que del total de
En la imagen adjunta presento la pantalla que WEKA desplegó inmediatamente después de haberle pedido que abriera el historial de reparaciones cuyo formato especifiqué en mi ensayo anterior. El diagrama de barras que aparece en esta misma captura de pantalla proporciona un informe del número de casos que en cada reparación, correspondió a una marca de horno de microondas en particular (pulse sobre la imagen para agrandarla). Así por ejemplo, vemos que del total de  reparaciones efectuadas, se registraron 10 casos en los que la marca del horno resultó ser General Electric, otros 8 en los que fue Amana y así sucesivamente para los demás casos. Asimismo, al seleccionar la localización de la falla en el recuadro de atributos, notamos que en el 22% de los casos, las fallas se producen en el circuito de alta tensión (pulse sobre la imagen de la derecha). Antes de reparar mi primer horno de microondas, yo no tenía idea de qué tan importante podía ser ese dato, mientras averiguaba porqué ese horno hacía tanto ruido y no calentaba.
reparaciones efectuadas, se registraron 10 casos en los que la marca del horno resultó ser General Electric, otros 8 en los que fue Amana y así sucesivamente para los demás casos. Asimismo, al seleccionar la localización de la falla en el recuadro de atributos, notamos que en el 22% de los casos, las fallas se producen en el circuito de alta tensión (pulse sobre la imagen de la derecha). Antes de reparar mi primer horno de microondas, yo no tenía idea de qué tan importante podía ser ese dato, mientras averiguaba porqué ese horno hacía tanto ruido y no calentaba. No obstante, es claro que esas estadísticas no nos van a servir de mucho a la hora de identificar con precisión, los componentes y las acciones correctivas que debemos realizar para consumar la reparación. Es por ello que apelé a las técnicas de la minería de datos para implementar WEKAProMic: el sistema de aprendizaje de máquina cuyo modelo conceptual propuse en Aprendizaje de máquina para legos: la inteligencia artificial explicada con “manzanitas”.
No obstante, es claro que esas estadísticas no nos van a servir de mucho a la hora de identificar con precisión, los componentes y las acciones correctivas que debemos realizar para consumar la reparación. Es por ello que apelé a las técnicas de la minería de datos para implementar WEKAProMic: el sistema de aprendizaje de máquina cuyo modelo conceptual propuse en Aprendizaje de máquina para legos: la inteligencia artificial explicada con “manzanitas”. Se le llama clasificación (clustering) al procedimiento que emplea WEKA y otros programas de minería de datos para dividir una base de conocimientos en grupos con atributos afines. En nuestro caso particular, la base de conocimientos está representada por el historial de reparaciones en hornos de microondas. La estrategia a seguir entonces es realizar varios experimentos hasta que la máquina descubra, a través de un algoritmo de clasificación, el grupo en el que mejor encaja el caso del horno de microondas que se ha de reparar.
Se le llama clasificación (clustering) al procedimiento que emplea WEKA y otros programas de minería de datos para dividir una base de conocimientos en grupos con atributos afines. En nuestro caso particular, la base de conocimientos está representada por el historial de reparaciones en hornos de microondas. La estrategia a seguir entonces es realizar varios experimentos hasta que la máquina descubra, a través de un algoritmo de clasificación, el grupo en el que mejor encaja el caso del horno de microondas que se ha de reparar. En la imagen adjunta muestro el resultado del primer experimento, en el que le solicité a WEKA dividir el historial en 10 grupos. Como se ve, el caso del horno que hacía ruido y no calentaba quedó clasificado en el grupo (cluster) No. 1; pero aunque la máquina intuyó que la falla podía estar en el circuito de alto voltaje y que el reemplazo de componente(s) debía ser la primera acción correctiva a efectuar, ésta no fue capaz de especificar cuáles debían ser esos componentes (pulse sobre la captura de pantalla para agrandarla). Tuve que llevar a cabo 7 experimentos en total para descubrir cuáles podrían ser los componentes a
En la imagen adjunta muestro el resultado del primer experimento, en el que le solicité a WEKA dividir el historial en 10 grupos. Como se ve, el caso del horno que hacía ruido y no calentaba quedó clasificado en el grupo (cluster) No. 1; pero aunque la máquina intuyó que la falla podía estar en el circuito de alto voltaje y que el reemplazo de componente(s) debía ser la primera acción correctiva a efectuar, ésta no fue capaz de especificar cuáles debían ser esos componentes (pulse sobre la captura de pantalla para agrandarla). Tuve que llevar a cabo 7 experimentos en total para descubrir cuáles podrían ser los componentes a  reemplazar en este caso. La imagen de la derecha ilustra cómo en el sexto experimento la herramienta encontró similitudes muy marcadas entre las tendencias de cada uno de los atributos del grupo 10 y las características del caso por resolver, razón de sobra para clasificarlo en ese grupo. Note cómo la mayoría de los atributos entre ambas columnas de datos se parecen, y cómo aquellos que al principio no eran conocidos (nombre del atributo=Missing), los infiere la máquina a partir de esas similitudes.
reemplazar en este caso. La imagen de la derecha ilustra cómo en el sexto experimento la herramienta encontró similitudes muy marcadas entre las tendencias de cada uno de los atributos del grupo 10 y las características del caso por resolver, razón de sobra para clasificarlo en ese grupo. Note cómo la mayoría de los atributos entre ambas columnas de datos se parecen, y cómo aquellos que al principio no eran conocidos (nombre del atributo=Missing), los infiere la máquina a partir de esas similitudes. Y fue en el séptimo experimento en donde finalmente conseguí que la herramienta me mostrara el componente que a su juicio debía ser reemplazado. Como se infiere de la imagen adjunta, éste resultó ser ni más ni menos que el magnetrón. Y aunque a simple vista uno pensaría que este experimento es el mismo que el anterior, en este último el número de grupos en los que dividí el historial fue de 20, en contraste con los 16 del anterior. Asimismo, note que el grupo 10 de este experimento consta de 7 casos, a diferencia de los 9 que se juntaron cuando ensayé con 16 grupos.
Y fue en el séptimo experimento en donde finalmente conseguí que la herramienta me mostrara el componente que a su juicio debía ser reemplazado. Como se infiere de la imagen adjunta, éste resultó ser ni más ni menos que el magnetrón. Y aunque a simple vista uno pensaría que este experimento es el mismo que el anterior, en este último el número de grupos en los que dividí el historial fue de 20, en contraste con los 16 del anterior. Asimismo, note que el grupo 10 de este experimento consta de 7 casos, a diferencia de los 9 que se juntaron cuando ensayé con 16 grupos. Sin embargo, no hay que olvidar que para que un caso se convierta en uno de éxito, el responsable de la reparación debe conocer las medidas de seguridad que debe observar para no sufrir un accidente, así como aprender a probar componentes y saber cómo medir variables eléctricas. En el siguiente ensayo explicaré cómo se debe descargar el capacitor que todo horno de microondas trae consigo, en su circuito de alta tensión.
Sin embargo, no hay que olvidar que para que un caso se convierta en uno de éxito, el responsable de la reparación debe conocer las medidas de seguridad que debe observar para no sufrir un accidente, así como aprender a probar componentes y saber cómo medir variables eléctricas. En el siguiente ensayo explicaré cómo se debe descargar el capacitor que todo horno de microondas trae consigo, en su circuito de alta tensión.




































































 Objetivo:
Objetivo:


 4.1 Taller No. 2:
4.1 Taller No. 2: 
















































